AI can’t fully eliminate bias in decision-making, but it can help reduce it when used correctly. However, biased data, flawed algorithms, and over-reliance on AI pose significant risks. Here’s the key takeaway:
- AI mirrors its training data: If the data is biased, AI will replicate and even scale those biases.
- Bias reduction tools exist: Techniques like data filtering, counterfactual reasoning, and real-time monitoring can help identify and address bias.
- Human oversight is critical: Combining AI with human review ensures better accountability and reduces errors.
- Challenges remain: Defining "fairness" is complex, and tradeoffs between fairness and accuracy often arise.
While AI offers tools to address bias, its effectiveness depends on the quality of data, ethical design, and human involvement. It’s not a perfect solution, but it’s a step toward more balanced decision-making.
How Bias in Training Data Destabilizes AI Decisions
sbb-itb-d5e73b4
How AI Identifies and Reduces Bias
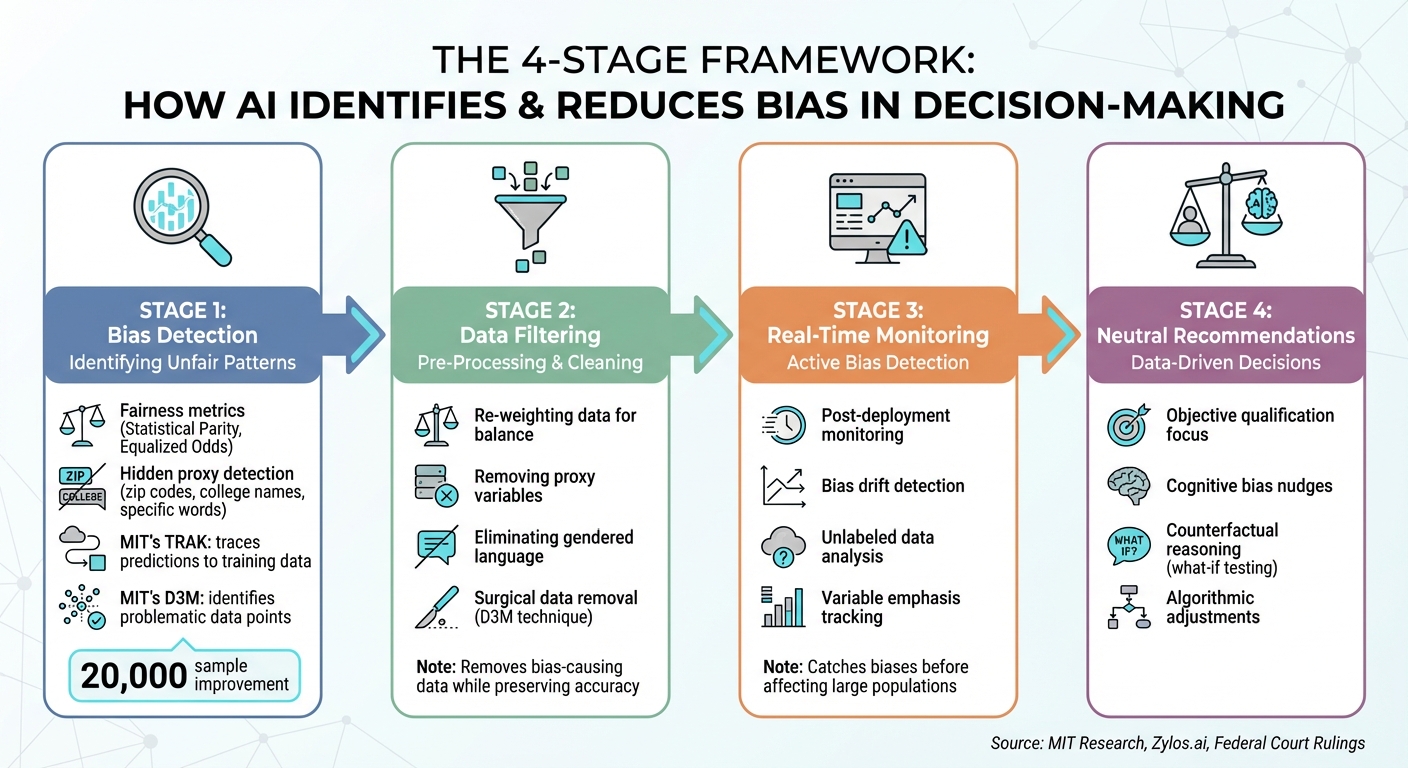
How AI Identifies and Reduces Bias: A 4-Stage Framework
AI has an impressive ability to spot unfair patterns that often go unnoticed during manual reviews. By using fairness metrics like Statistical Parity and Equalized Odds, it can pinpoint performance differences across demographic groups with a level of precision that human auditors simply can’t match [2]. It can also uncover hidden proxies – variables that seem neutral at first glance, like zip codes, college names, or even specific words like "executed" or "captured", but may encode discriminatory patterns [1].
Advanced methods, such as MIT‘s TRAK, take it a step further by tracing incorrect predictions back to the exact training data that influenced them. Another MIT innovation, the D3M technique, identifies problematic data points that contribute to bias, reducing sample loss by 20,000 compared to older methods [4].
"There are specific points in our dataset that are contributing to this bias, and we can find those data points, remove them, and get better performance."
– Kimia Hamidieh, Graduate Student, MIT [4]
AI also uses counterfactual reasoning to test fairness by simulating changes in a single protected attribute. For instance, if a loan approval changes solely based on race, the system flags the decision as biased [2]. This "what-if" testing operates at a scale far beyond what humans could manage, setting the stage for targeted bias-reduction strategies.
Data Filtering to Remove Bias
Before training even begins, AI systems can clean datasets by removing biased inputs. Pre-processing techniques play a central role here, such as re-weighting data to balance class distributions or excluding variables that act as proxies for protected characteristics [2]. Examples include eliminating gendered language from job descriptions (e.g., "women’s chess club"), filtering out zip codes tied to racial segregation, and removing college names that hint at socioeconomic status [1].
But simply removing data isn’t always enough. Past AI deployments have shown that algorithms often adapt by finding new ways to replicate historical patterns, even after filtering efforts.
To address this, modern techniques take a more surgical approach. Instead of cutting out large chunks of data – which can hurt accuracy – methods like MIT’s D3M focus on isolating the specific examples that drive bias. As Andrew Ilyas, a Stein Fellow at Stanford University, explains:
"When you have tools that let you critically look at the data and figure out which datapoints are going to lead to bias or other undesirable behavior, it gives you a first step toward building models that are going to be more fair and more reliable."
– Andrew Ilyas, Stein Fellow, Stanford University [4]
While pre-processing helps clean the data, addressing bias during active use requires additional tools.
Real-Time Bias Detection
AI doesn’t stop at pre-processing; it can also monitor for bias as decisions are being made. Post-deployment tools are designed to detect bias drift – where models gradually become biased as they interact with new real-world data [2]. These tools often analyze unlabeled data to uncover hidden sources of bias by examining which variables the model emphasizes during predictions [4]. This is particularly crucial given that regulations like GDPR restrict the collection of sensitive personal data, even though understanding group impacts is key to fairness testing.
For example, prior studies have highlighted disparities in name-based evaluations [1]. Real-time detection tools can catch these biases before they affect a large number of people. Once identified, these biases can be corrected through algorithmic adjustments, as described below.
Neutral Decision Recommendations
AI can also help counteract human biases by providing data-driven alternatives. It acts as a sort of "nudge", encouraging human decision-makers to focus on objective qualifications and avoid common cognitive pitfalls [7]. In a notable case, the July 2024 Mobley v. Workday ruling, a federal judge observed:
"Workday’s software is not simply implementing in a rote way the criteria that employers set forth, but is instead participating in the decision-making process."
– Federal Judge, Mobley v. Workday [1]
Limitations and Risks of Using AI to Reduce Bias
AI has the potential to identify and address bias, but it comes with substantial risks. Instead of eliminating discrimination, it can inadvertently make it worse. The fairness of AI is directly tied to the quality of the data it learns from – when that data is flawed, the consequences can ripple out to affect millions.
How Training Data Can Amplify Bias
AI systems learn from historical data, which often carries the weight of decades of societal prejudice and inequality [8][9]. If the data itself is skewed, AI can end up reinforcing those distortions. For instance, datasets that reflect longstanding biases can lead to outputs that perpetuate these inequalities [8]. Even the process of labeling data, often done by human annotators, can unintentionally embed stereotypes, further entrenching bias in the AI’s results [9].
Take facial recognition technology as an example: studies have shown that some commercial systems have error rates below 1% for white men but over 30% for darker-skinned women [9]. With nearly 90% of companies using some form of AI in hiring by late 2025, these biases can have wide-ranging consequences [3]. Such data-level issues make AI systems vulnerable to flawed decision-making, creating a domino effect of biased outcomes.
Over-Reliance and Feedback Loops
Bias in data isn’t the only problem – over-reliance on AI poses its own risks. Many people assume AI outputs are inherently neutral, leading to uncritical acceptance, especially under tight deadlines [5][9]. This blind trust becomes even riskier when biased AI decisions influence human behavior, which then generates new data that reinforces the original bias. Predictive policing is a prime example: algorithms direct patrols to certain neighborhoods based on historically biased arrest data, creating a feedback loop that deepens discrimination.
Another issue is the tension between fairness and other priorities like accuracy or profitability. For example, a 2025 study revealed that enforcing demographic parity in lending decisions reduced profit margins [2]. This tradeoff highlights how fairness can sometimes conflict with business objectives.
The Challenge of Defining Fairness in AI
Even when bias in data is addressed, defining fairness itself remains a major hurdle. There’s no single, universal definition of fairness, and different metrics often clash with one another [2][9]. For instance, statistical parity aims for equal outcomes across groups, while equalized odds focus on ensuring similar accuracy rates. These goals are mathematically incompatible in many cases, creating what’s known as a "Pareto frontier", where improving one aspect of fairness comes at the expense of another [2].
The real-world implications of these challenges are stark. In October 2024, researchers at the University of Washington tested GPT-4, Claude, and Gemini on resume ranking. When comparing identical resumes with only the names changed, the systems chose white-associated names 85% of the time, Black-associated names just 9% of the time, and in some cases, Black male names were favored 0% of the time [1].
"Reductionist representations of fairness often bear little resemblance to real-life fairness considerations, which in practice are highly contextual."
– Zylos.ai Research Report [2]
Even removing explicit identifiers like race or gender from training data doesn’t fully solve the problem. AI can use proxies – such as zip codes, college names, or specific phrases – to recreate biased patterns [1][2].
How to Improve AI’s Ability to Reduce Bias
AI alone can’t eliminate bias – it requires thoughtful intervention at every stage. From building datasets to reviewing decisions post-deployment, intentional safeguards are necessary. Without these measures, even well-meaning systems can fall back into biased behaviors.
Combining AI with Human Oversight
Human judgment is critical, especially in high-stakes scenarios. Human-in-the-Loop (HITL) systems provide checkpoints where humans review algorithmic recommendations before they become final decisions. This approach is particularly important in fields like finance and recruitment, where the outcomes can significantly impact lives [2][11].
By combining HITL systems with diverse development teams, organizations can catch blind spots early. Structures like AI Ethics Boards and roles such as Chief AI Ethics Officers further enhance accountability and governance [2][11].
For example, New York City now requires annual independent bias audits for AI-driven hiring tools. Companies that fail to comply face fines, signaling a shift toward mandatory fairness measures rather than voluntary guidelines [11].
Training AI on Debiased Datasets
The quality of training data has a direct impact on AI performance. In December 2024, researchers at MIT, including Kimia Hamidieh and Saachi Jain, introduced Data Debiasing with Datamodels (D3M). This method identifies bias-causing data points and retrains the model to improve accuracy for underrepresented groups while retaining more data samples. Using a tool called TRAK, the team pinpointed training examples that led to poor performance on minority subgroups and retained 20,000 more samples compared to older balancing methods [6][4].
"Many other algorithms that try to address this issue assume each datapoint matters as much as every other datapoint. In this paper, we are showing that assumption is not true. There are specific points in our dataset that are contributing to this bias, and we can find those data points, remove them, and get better performance."
– Kimia Hamidieh, Graduate Student, MIT [6]
This method not only maintains overall model accuracy but also enhances performance for underrepresented groups. It can even detect hidden biases in unlabeled datasets by tracing which data points influence the model to adopt certain patterns, such as associating race or gender with medical diagnoses [10].
Pairing these technical solutions with human-centered strategies helps tackle residual cognitive biases that algorithms alone can’t address.
Using Platforms Like Aidx.ai
Beyond improving algorithms, addressing human bias is equally important. Platforms like Aidx.ai focus on mitigating cognitive biases that people bring to their interactions with AI. These biases – like confirmation bias, expediency bias, or the tendency to accept AI outputs without question – can undermine fairness [5].
Aidx.ai uses techniques inspired by Cognitive Behavioral Therapy (CBT) and Dialectical Behavior Therapy (DBT) to help users reflect on their assumptions before acting on AI recommendations. The platform encourages structured decision-making, guiding users to question their initial reactions, surface hidden assumptions, and employ tools like pre-mortem analysis (imagining how a decision could fail) to test their reasoning [5].
This approach combines the strengths of debiased AI systems with tools that enhance human judgment. While AI can identify patterns in data, it’s up to people to recognize when their own mental shortcuts are amplifying those patterns. Together, these strategies offer a more comprehensive path to reducing bias.
Conclusion: Can AI Truly Eliminate Bias?
The straightforward answer is no – AI cannot completely eliminate bias in decision-making. While it can reduce bias to more manageable levels, perfect fairness is mathematically out of reach. Research highlights this challenge: improving group fairness by 10–15% often leads to a 2–5% drop in overall model accuracy [2][12]. These tradeoffs emphasize the need for ongoing human involvement.
Bias doesn’t just stem from data; it’s also influenced by human cognitive biases – how we frame questions for AI and interpret its outputs [5]. Tools like Aidx.ai aim to address this by helping users identify and challenge their assumptions. These platforms combine advanced algorithms with tools to enhance human decision-making.
"The ultimate goal is not perfect mathematical fairness (which may be impossible due to inherent tradeoffs) but rather transparent, accountable systems that minimize harm and promote equitable outcomes." – Zylos.ai Research [2]
FAQs
What’s the difference between “bias” and “unfairness” in AI decisions?
Bias in AI refers to systematic errors or tendencies in decision-making, often stemming from issues in the training data or the way a model is designed. Unfairness, however, focuses on discriminatory or inequitable outcomes that can arise, not just from bias, but also from broader ethical and societal factors. While bias is more of a technical issue, unfairness deals with the real-world consequences on individuals or groups.
How can AI be tested for bias without collecting sensitive demographic data?
AI systems can be evaluated for bias even without relying on sensitive demographic data. One effective method is through correspondence experiments. These experiments involve altering application materials – such as names, addresses, or other subtle indicators – to imply different demographic groups. The AI’s responses are then analyzed for any disparities in treatment. This technique has been particularly useful in uncovering bias in processes like hiring decisions.
When should a human override an AI recommendation?
Humans need to step in and override AI recommendations when those suggestions are flawed, biased, or clash with ethical principles. This is especially important in situations where the AI’s output is discriminatory, undermines fairness, or poses potential harm. Human judgment becomes essential when AI explanations are unclear or misleading, ensuring that decisions reflect societal values and comply with legal standards. At the core, human intervention is about preventing bias, maintaining fairness, and safeguarding ethical decision-making.